![[ETL] Multithreading](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbyUpRj%2FbtrCJvKfdff%2FAYFvRpMnhtkG3h7r4sC0Kk%2Fimg.png)
출처 : SNUON / 운영체제의 기초: 쉽게 배우는 운영체제 원리 / 서울대 홍성수 교수님

병렬성이 필요할 때마다 프로세스 만드는 건 오버헤드가 너무 큼
잘 생각해보면 프로세스에서 context는 자원이고 thread of control(execution stream)이 실행 주체다.
ex) CPU register : cpu 자원, memory context : 메모리 자원
그럼 thread of control은 여러 개 있어도 되지 않을까?
자원은 한 프로세스 분량만 유지하고 쓰레드들이 자원을 나눠서 쓴다
이제 쓰레드가 execution entity, 즉 CPU를 할당받는 주체다.
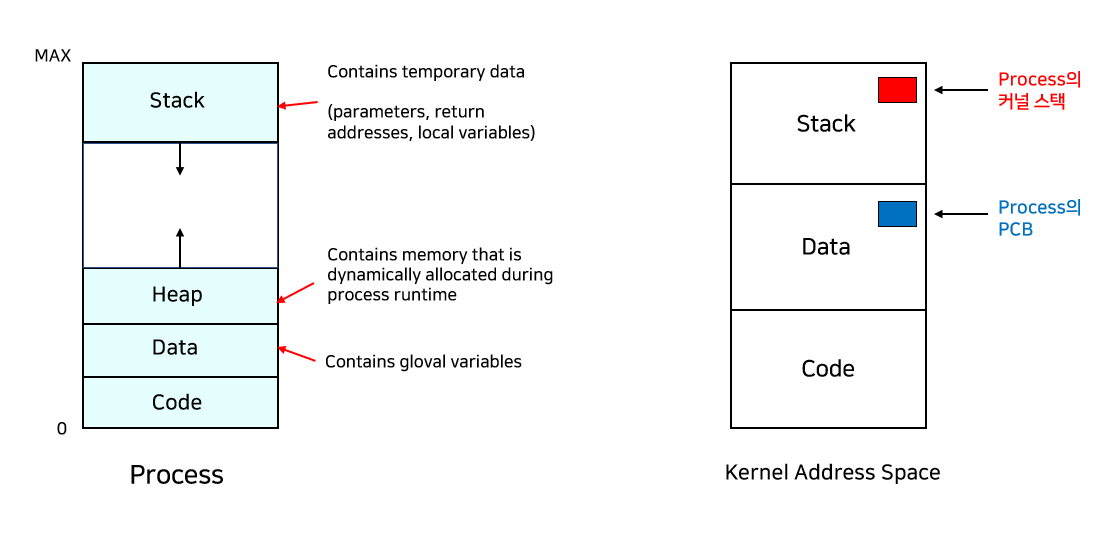
하나의 프로세스가 여러 개의 스택을 갖는다.
즉, 쓰레드들이 address space, resource는 공유하는 대신 각각의 스택을 갖는다.
추가로, 커널 메모리 공간에는 각 쓰레드들의 Thread ID도 저장해야 하고, TCB(Thread Control Blcok)도 만들어줘야 한다.
--------------------------------------------------------------------------------------------------------------
참고
지금 내가 제일 헷갈리는 부분 정리해뒀음

--------------------------------------------------------------------------------------------------------------


process : run-time process
task : design-time process


multi threading 의 목적
- 값싸게 concurrency 얻겠다.
(thread 생성, thread context switch 엄청 값싸다. 스택 하나 기껏해봐야 4K 밖에 안된다...)
- 반응성이 확 상승.
커널의 구현
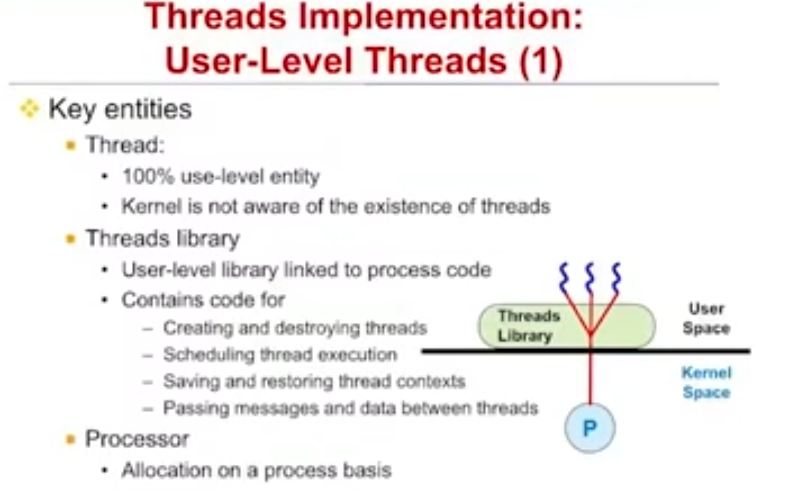


User-level Implementation
- 커널이 전혀 모르게 구현하는 방법
(Old UNIX는 멀티쓰레딩 서비스 안해줘서 이렇게 구현할 수밖에 없다)
- 유저 레벨에서 스택, TCB, 스케줄러 전부 구현해야함.
- nonpreemptive scheduling : cpu yield 함수 호출하면 된다
- preemptive scheduling : 안된다
ex) 하나의 쓰레드가 read 인터럽트 걸어도 process가 통째로 blocking
ex) read 작업 끝나서 인터럽트 와도 OS가 어느 쓰레드에 대한 인터럽트인지 알 수 없어서 전달 X
- 과학 계산 같이 input 계속 받을 필요 없을 땐 좋다. reactive 시스템에선 못쓴다.



Kerenel-level implementation
- 스택, TCB, 스케쥴링 등을 커널이 다 해준다
- preemptive scheduling도 잘 된다
- 예를 들어, Windows가 커널 레벨 쓰레드를 지원한다
- 과학 계산할 때는 오버헤드로 인해 별로 안좋다

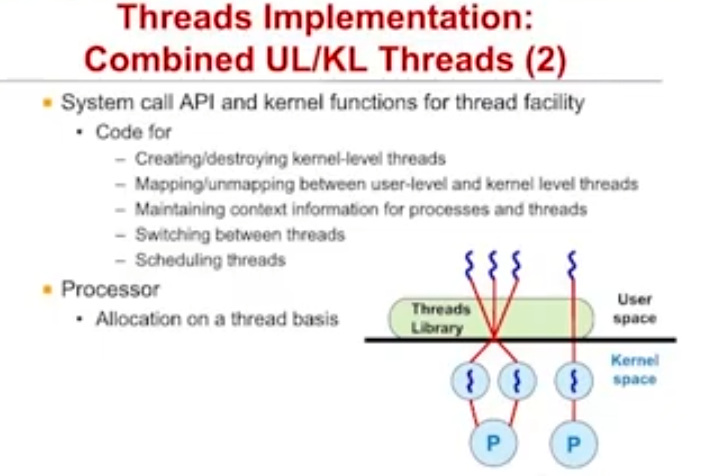
둘의 장점만 결합

응용 프로그래머 관점에서 multi-threading을 사용할 때에는 POSIX Pthread API가 가장 애용된다.
POSIX : UNIX 계열 변종 OS들의 API를 표준화하려고 만든 API
Pthread : POSIX에서 멀티쓰레딩에 관한 부분

'CS > 운영체제' 카테고리의 다른 글
| 메모리 관리 (0) | 2022.05.24 |
|---|---|
| Deadlock (0) | 2022.05.24 |
| [ETL] Process Creation and Termination (0) | 2022.05.22 |
| [ETL] Context Switching (0) | 2022.05.22 |
| [ETL] Processes and Threads - Process Scheduling (0) | 2022.05.16 |